/* Transfers ownership of a string from the function to the variable. */ template = "XXXXXX"; my_str = generate_string (template); //template的所有权从系统管理到my_str了,因为template原本就没有所有权 /* template是用const修饰的,generate_string的参数也是const修饰的,他们本身都没有内存的所有权 */
/* No ownership transfer. */ print_string (my_str); //没有发生所有权转移
/* Transfer ownership. We no longer have to free @my_str. */ //这里发生所有权转移,猜测my_str的形参类型定义的是gchar,没有const修饰 g_value_take_string (&value, my_str);
/* We still have ownership of @value, so free it before it goes out of scope. */ g_value_unset (&value);
/** * g_value_take_string: * @value: (transfer none): an initialized #GValue * @str: (transfer full): string to set it to * * Function documentation goes here. */
/** * generate_string: * @template: (transfer none): a template to follow when generating the string * * Function documentation goes here. * * Returns: (transfer full): a newly generated string */
// The __GTK_H_INSIDE__ symbol is defined in the gtk.h header // The GTK_COMPILATION symbol is defined only when compiling // GTK itself #if !defined (__GTK_H_INSIDE__) && !defined (GTK_COMPILATION) #error"Only <gtk/gtk.h> can be included directly." #endif
#pragma once //Time Class definition //member functions are declared in time.cpp
//prevent multiple inclusions of header #ifndef TIME_H #define TIME_H
//time class definition classtime { public: Time();//constructor voidsetTime(int, int, int);//set hour, minute and second voidprintUniversal()const;//print time in universal-time format voidprintStandard()const;//print time in standard-time format
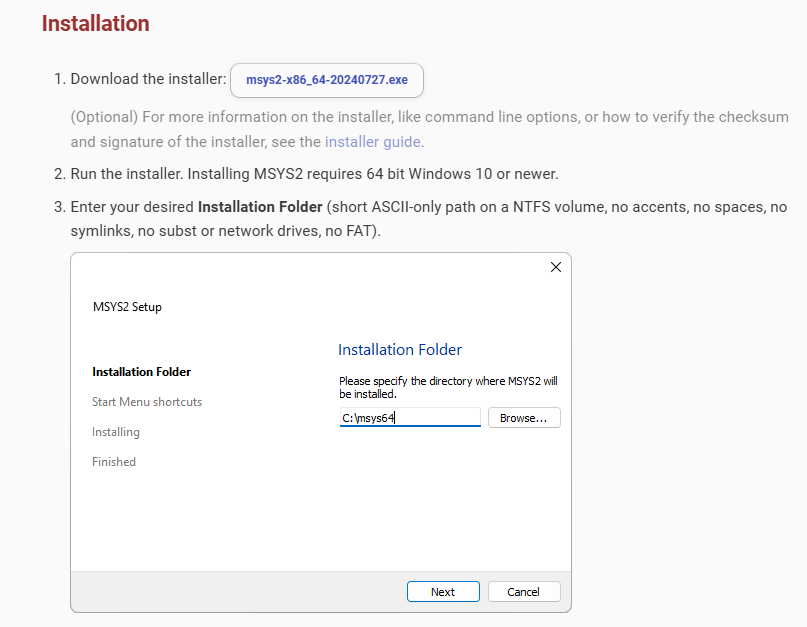
There are various methods to install GTK on Windows development machines.
MSYS2
This method is based on the packages provided by MSYS2, which provides a UNIX-like environment for Windows. Both of these repositories also provide packages for a large number of other useful open source libraries.
gvsbuild
This method provides scripts to build the GTK stack from source and outputs libraries and tools that can be consumed by Visual Studio or Meson based projects.
defvectorize_sequences(sequences, dimension=10000): # Create an all-zero matrix of shape (len(sequences), dimension) results = np.zeros((len(sequences), dimension)) for i, sequence inenumerate(sequences): results[i, sequence] = 1.# set specific indices of results[i] to 1s return results
# Our vectorized training data x_train = vectorize_sequences(train_data) # Our vectorized test data x_test = vectorize_sequences(test_data) # Our vectorized labels y_train = np.asarray(train_labels).astype('float32') y_test = np.asarray(test_labels).astype('float32')
model = models.Sequential() model.add(layers.Dense(16, activation='relu', input_shape=(10000,))) model.add(layers.Dense(16, activation='relu')) model.add(layers.Dense(1, activation='sigmoid'))
安装过程进行到Setting up the package cache时会很慢,如果有杀毒软件,会更慢,另外安装过程可能会下载一些包,所以安装过程需要保持联网。稍等,进度条跑完就安装完成了。如果一直卡住不动,可以试下重启安装程序。重启安装程序时,它会提示安装位置非空,让你换一个安装位置,可以去删了那个文件夹。